barriers
Overview
Coordinating the execution of multiple threads often requires efficient implementation of synchronization primitives from the standard library and/or operating system.
As an operating system and library designer,
-
How can we implement primitives like locks, mutex and barriers to scale efficiently on many threads?
-
How can we minimize latency and memory contention?
-
Can we synchronize separate processes, possibly across independent machines?
These are the questions I tried to answer in a project I completed in Advanced Operating Systems at Georgia Tech where I implemented and compared various barrier algorithms discussed in the seminal paper,
Mellor-Crummey, J. M., & Scott, M. L. (1991). Algorithms for Scalable Synchronization on Shared-Memory Multiprocessor. Computer Systems. https://dl.acm.org/doi/10.1145/103727.103729
What are barriers?
A barrier is a synchronization primitive that requires all threads to enter the barrier before any threads can exit and continue execution.
Barriers are often used to synchronize stages of computation. For example, if multiple threads are parallelizing a discrete time simulation, you might want to ensure the state of the world in the previous time step is fully computed before you simulate the current time step.
Shared Memory Spin Barriers
Spin barriers fall into one category of barriers that relies on busy spinning on shared memory location as a means of communicating between different threads.
The memory locations often hold shared booleans like release or sense.
Waiting threads enter a hot loop like while(!release); or while(sense != localsense) to continuously check when they can leave the barrier.
Spin barriers requires no involvement from the operating system but has the potential to starve the CPU from doing useful work on the thread that has to reach the barrier. An alternative is to use locks or barriers that involves the OS scheduler so the waiting thread can go to sleep.
The conventional wisdom is that one should use a spin lock/barrier if the overhead of invoking the operating system is higher than the expected wait time for the lock/barrier. But this is a hotly debated topic in the community.
-
Linus Torvalds’s take on spinlocks in user space programs.
-
Post by matlad on rust mutex and a practical comparison between spinning vs using standard library mutex.
Counting Barrier
Counting barrier is a simple implementation that relies on a single atomic counter variable and multiple threads busy spinning on a release variable.
The last thread to enter a barrier signals to all other threads by flipping the release or sense boolean.
Advantages: Simple, fewest assembly instructions.
Disadvantages: In cache coherent CPUs, each thread will cache the shared memory location it is spinning on in its L1 cache. A thundering herd then occurs when the shared location is changed and all threads invalidate their cache row and refetch the updated value from the core who cache line is in the modified state. The amount of concurrent bus traffic scales as number of threads increase. This has the potential to stall the CPU and reduces the overall efficiency of the barrier.
MCS Tree Barrier
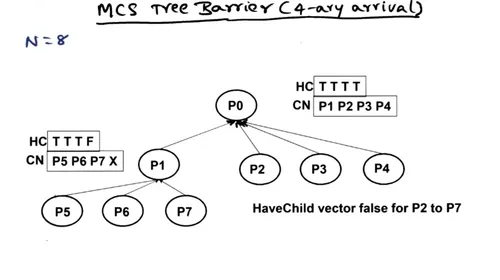
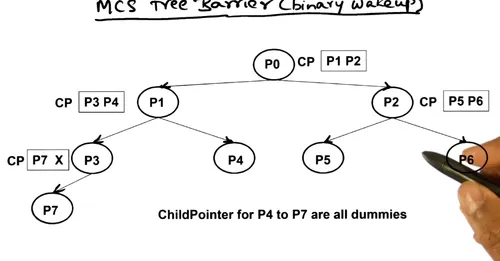
MCS proposes a solution that alleviates memory contention by distributing the spin variable in a tree based structure.
The tree structure is represented as an array of interconnected nodes. Quite uniquely, the structure encodes both a 4-ary arrival tree and a binary wake up tree all in a single array of node structs.
When a threads arrives at the barrier, it first spins until all of its children have arrived. Then it signals to its parent in the arrival tree. Then, it spins until the parent in the wake up tree signals to continue execution. Finally, it signal its children to continue and leaves the barrier.
Advantages: Avoids single spin location for all threads.
Disadvantages: Code is more complex.
Which one is better?
Like most engineering decisions, it somewhat depends!
Using OpenMP to spin up multiple threads, we can compare the runtime of the two barriers.
#pragma omp parallel shared(num_threads)
{
struct timespec start, end;
clock_gettime(CLOCK_MONOTONIC, &start);
for (int i = 0; i < 1000000; i++)
{
barrier();
}
clock_gettime(CLOCK_MONOTONIC, &end);
printf(
"1000000 iterations took about %.5f seconds\n",
((double)end.tv_sec + 1.0e-9 * end.tv_nsec) -
((double)start.tv_sec + 1.0e-9 * start.tv_nsec)
);
}
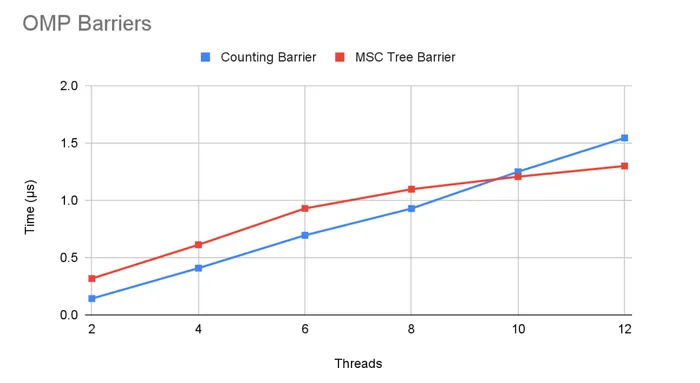
The graph above shows the average latency per iteration of the barrier.
As expected, the MSC tree barrier scaled better with the number of threads due to less contention on the bus. However, the counting barrier outperforms the tree barrier at low number of threads due to the simpler code. Often times, asymptotic behavior is not the only consideration. Constant factor and problem size matter!
MPI Barriers
To synchronize across machines, we must leverage a different mechanism of communication as shared memory and atomic operations are no longer possible between separate computers on the network.
MPI is an API for expressing explicit network communication between compute nodes. It is often used in scientific computing applications that run on many independent nodes of a supercomputing cluster.
For the project, I have implemented a tournament barrier and a dissemination barrier using OpenMPI.
Both of these algorithms does O(log(N)) rounds of coordinated communication between nodes to reach consensus that everyone has reached the barrier.
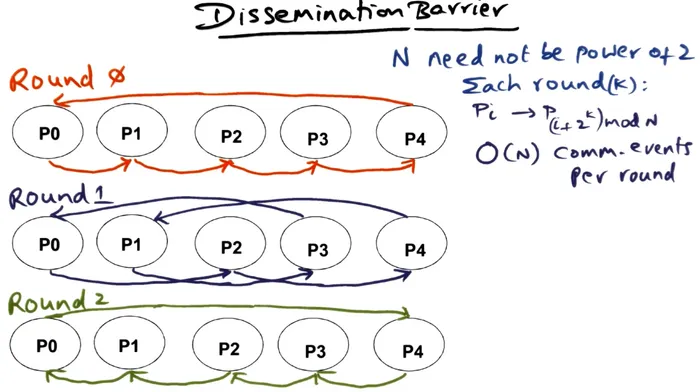
But like the shared memory barriers, Big O behavior does not tell the full story. The tournament barrier is actually twice as slow as the dissemination barrier due to a constant factor difference in the number of serial communication rounds required.
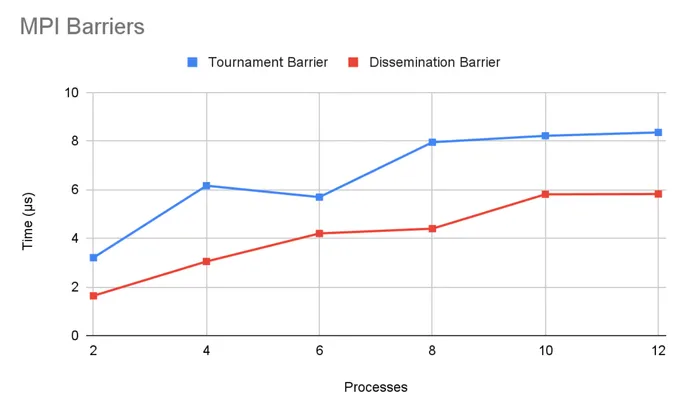
It is worth noting however that the tournament barrier is more efficient in the total amount of communication required despite requiring more rounds of serial communication. So there is an interesting tradeoff here between latency and bandwidth. The right solution would depend on the infrastructure the code is running on and the capabilities of the network topology!
Reflections
I really enjoyed this project. The algorithms are incredibly elegant and programming them in C was quite enjoyable.
This was also the first time I gained first hand experience with optimizing multi-threaded performance by eliminating false sharing situations. I was able to squeeze substantial performance out of the barriers by properly aligning memory allocation with cache line and padding structures appropriately such that each thread fully “owns” a L1 cache line.