deep3d-tf
Source | Presentation | Original Project
Citations
This project is a replication of the original work by Eric Junyuan Xie et al for educational purpose.
Xie, J., Girshick, R., & Farhadi, A. (2016, April 13). Deep3D: Fully automatic 2D-to-3d video conversion with deep convolutional Neural Networks. arXiv.org. https://arxiv.org/abs/1604.03650
Overview
Can we generate 3D footage from 2D frames?
3D perspective is all about depth, and the visual difference of an object’s position between our left and right eye (parallax) is what our brains perceive as depth.
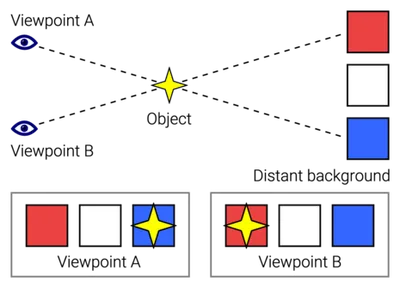
Deep3D aims to predict the right eye perspective using the left eye perspective as input. It does that by predicting depth of objects in an image and shifting image pixels accordingly and in-painting missing regions by smearing nearby pixels.
Background
This is a group project I completed in 2017 for a Computer Vision and Deep Learning course.
In this course, I built feed forward convolutional neural networks and back propagation from scratch using numpy, and learnt about different computer vision techniques and state of the art architectures then like LSTM.
A huge focus of the course is on classification, object detection and hybrid models for image annotation with NLP. For the final project, I wanted to explore something different. Inspired by emerging ML models for image and framerate up-scaling like DeepStereo, I wanted to see if there were other ideas for applying ML to videos.
After some research, I came across Deep3D and was impressed by the results. This led me to this project of replicating the paper’s finding. Having built the foundation of a ML framework in this class, I also wanted to see what a fully featured framework like TensorFlow has to offer.
Scope
The goal is to port the original Deep3D model written in MXNet, an academic deep learning framework, to another popular ML framework, TensorFlow.
In addition to porting the model, we had to write our own training pipeline as it was not open-sourced by the original author. This involved implementing sourcing scripts for curating 3D movie frames, and custom pipelines for queuing large amounts of image frames to the GPU and training a large neural network.
Architecture
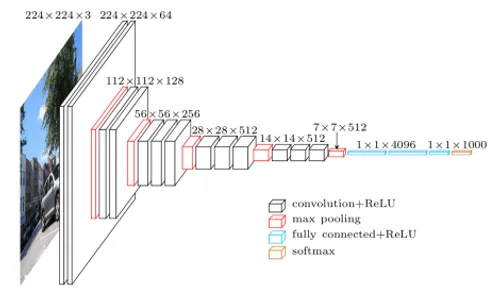
Deep3D builds upon a well known classification network, VGG, and introduces two additional components.
- up-sampling “de-convolution” branches to predict disparity (depth) in the input image
- a probabilistic selection layer that shifts and in-paints the output image
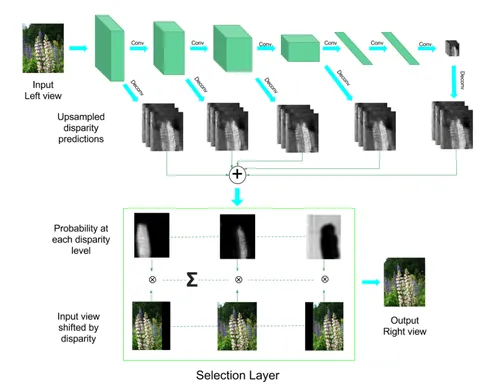
(Deep3D Architecture)
Disparity Prediction
A CNN at each convolution layer typically averages regions of activation to gradually reduce the data dimensions.
For depth estimation, the goal is generate a depth map of each pixel on the image. Therefore we want to preserve the dimensions of the image.
To achieve this, the paper proposes a series of branches at each convolution layer that effectively does the opposite of a convolution to up-sample an intermediate representation back to the original dimensions of the input image.
The idea is that these branches will leverage the powerful semantic understanding of the VGG network and learn the appropriate weights to output a representation of depth, which then can be fed to the selection layer.
Selection Layer
The selection layer takes in a 3 * Height * Width * 16 tensor, representing where each pixel might be as a normalized probability within 16 distinct levels of depth for the original image with its 3 color channels.
The product of the input and a stack of shifted views can then be reduced along the last dimension to effective compose a parallax image.
The implementation of the selection layer is technically interesting as it has to be differentiable for back propagation and training to function correctly.
Thankfully, tensorflow provides the building blocks for me to compose this custom vectorized tensorflow layer.
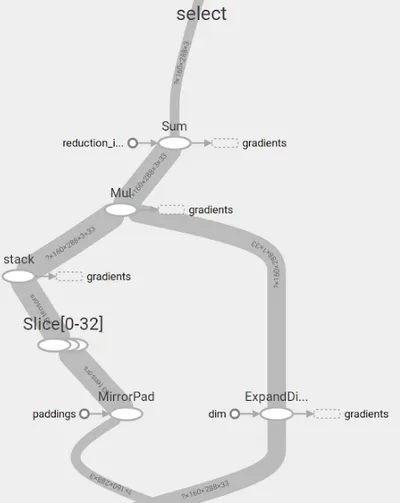
def select(masks, left_image, left_shift=16, name="select"):
"""
Input:
masks, shape N, H, W, S
left_image, shape N, H, W, C
Returns:
right_image, shape N, H, W, C
"""
_, H, W, S = masks.get_shape().as_list()
with tf.variable_scope(name):
# pad the tensor so that it can be shifted left or right and retain
# the total dimension. tf.pad has several modes to handle how the edges
# should be expressed
padded = tf.pad(
left_image,
[[0, 0], [0, 0], [left_shift, left_shift], [0, 0]],
mode="REFLECT",
)
# stack image with different level of shifts together
layers = []
for s in np.arange(S):
layers.append(tf.slice(padded, [0, 0, s, 0], [-1, H, W, -1]))
slices = tf.stack(layers, axis=4)
# finally multiply and reduce with the probability depth map to create
# the final composite of the right eye view
disparity_image = tf.multiply(slices, tf.expand_dims(masks, axis=3))
return tf.reduce_sum(disparity_image, axis=4)
Tensorboard also renders a nice visualization of it.
Training and Results
The training dataset consists of frames from 3D movies like the Hobbit trilogy and Step Up.
The network is initialized with pre-trained VGG weights, then trained on the set of movie frames using Mean Average Error as a cost metric.
Training only for 30 hours on a laptop (which did have a discrete GPU), the model did show signs of converging as it begins to estimate depth. Though the fidelity is definitely not on par with that of the original paper.
Here are some of the results.


(Estimated depth visualized)


Reflections
The ability of ML models to transfer its learning to different domain problem by generalizing the underlying semantic understanding is still one of the coolest thing I have learnt in computer science.
Overall, this was a very rewarding project and I learnt a lot about the challenges of training deep learning models.
Maximizing the efficiency of your hardware by keeping the CPU and GPU busy with minimal IO stall is non trivial and requires deep understanding of your system and software engineering principles typically outside of the study of machine learning.